Firepower Dual ISP
- Sep 15, 2023
- 4 min read
In this blog we are going to look at a few different ways to add redundancy for your Internet connection using Cisco Firepower. We will go through it two ways – We will look at a single firewall with two Internet Service Providers (“ISPs”) and two firewalls in a redundant pair. In a future post, we will dive into multiple data centers, and more advanced configuration options.
Dual ISP on a single FTD
For this lab, we will use a single Cisco Firepower Threat Defense (“FTD”) appliance, with multiple ISP connections.
The topology is simple:

Use Case
If ISP1 goes down, the FTD should automatically begin using ISP2. The impact to Client1 should be minimal. Currently, ISP1 is up and running, our job is to add ISP2 for redundancy.
Configuration
Step 1: Configure the G0/2 interface on FTD1. Nothing fancy:

Step 2: Add another default route pointing towards ISP2 but be sure to change the metric to something greater than 1 (the default). Deploy changes.

Step 3: Test. I am using EVE-NG in my lab, so it is easy to disable a link. Let’s start by disabling the link between FTD1 and ISP1:

A Simple ping will suffice for testing.

Looking back at the path from the FTD to the ISP we see that ISP2 is now in the path.

Now let’s go back to the steady state and then disable the link between ISP1 and the Internet. Place your bets!

Oh, Oh!!

The problem is from the FTD perspective, the default route to 172.16.1.1 is still good. Let’s fix it.
Step 4: Configure an IP SLA (SLA Monitor). We are going to keep this simple, but you can/should adjust the timers and other items in production:
Objects ---> Object Management ---> SLA Monitor ---> Add SLA Monitor

Here we are simply saying if Google is reachable, our route is good.
Step 5: Attach the new SLA Monitor object to the default route pointing to ISP1 and deploy changes.

Step 6: Test again.

Dual ISPs with Redundant FTDs
Here we are going to add a few things to the lab for full redundancy:

In this design, SW2, SW3, and SW4 are operating at Layer 2 only. This allows each FTD to use either ISP, when available. The FTDs are configured in a high availability pair:

The routing from the previous section is still in place. To refresh your memory:

The Problem

We have a standard HA configuration on the FTDs, using mostly defaults. The issue here is, if the link towards ISP1 goes down, the HA will trigger, and we will failover to FTD2. This is acceptable, but for this design, I would prefer to not failover if just one ISP is down.
We can change the Failure Limit to require two interfaces to go down instead of one:

This would not work either as the “Inside” interface is not redundant. If both ISP interfaces are up, but the Inside goes down, we have a sad story.
We could remove the cross connects between the FTDs and SW3/SW4. This way if ISP1 is down, we would failover to FTD2 which has access to ISP2. I don’t hate it, but I’m not in love with it either.
Let’s think about the outside (ISP) interfaces only. What would have to take place for FTD1 to not have Internet access, but FTD2 is, okay? Of course, both cables on FTD1 could go down, but that is a stretch. The only other way is hardware failure on FTD1, which would cause a failover anyway.
Of course, we could also overengineer the solution and create additional inside interfaces and use routing, redundant interfaces, IP SLAs, PBR, etc.… All of this would work and in certain environments it is a requirement.
For our pretend scenario, the best option is to simply not monitor the outside interfaces and let the IP SLA we already configured choose the path. If both ISPs are down, we are down anyway, so the failover is pointless and just adds to the chaos of an outage. If the Inside interface goes down, we failover to FTD2 and are still in business. Same drill if there is a hardware failure on FTD1.
A slight detour…When you are designing redundant systems, you must consider complexity. Not what is necessarily complex for you, but what is complex for someone that didn’t do the design. Do not allow the biggest risk of an outage to be your risk mitigation solution. If something is extremely unlikely and easy to manually resolve if it comes to be, skip it. Do not be in the position where the one-in-a-million is resolved with a fancy design, which causes another one-in-a-million, which causes…I’m sure you see the point.
Now, let’s break stuff!

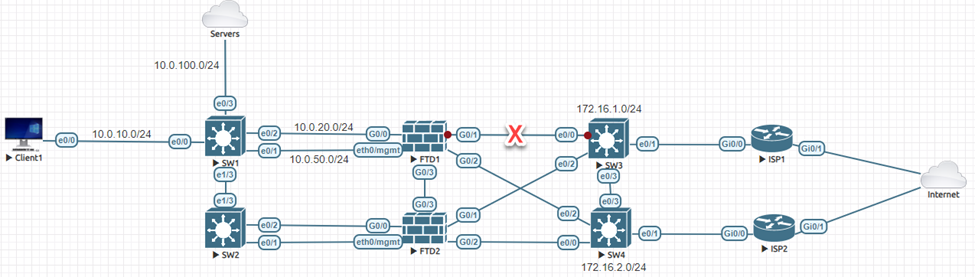

So far so good…

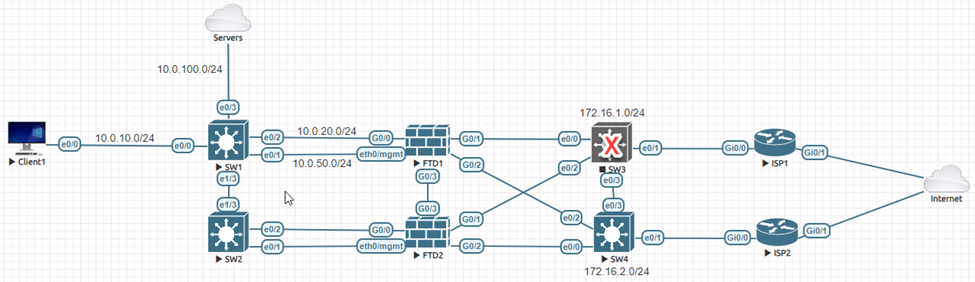

Nice.

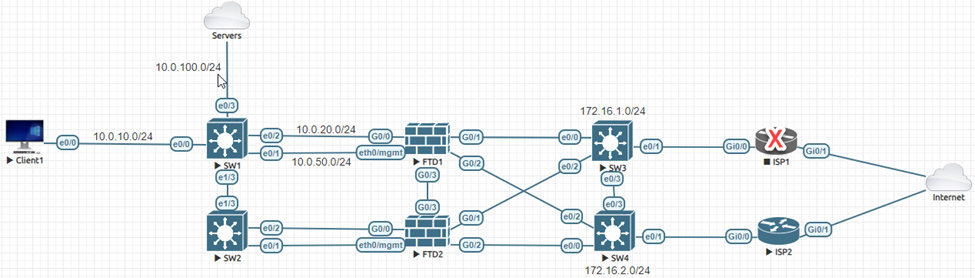

One more test…

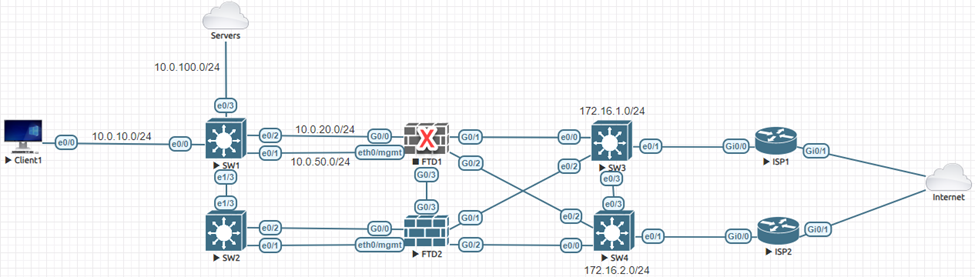

Our mission is complete!
How can CDA assist in enhancing your network security?
Our team includes Cisco Certified Internetwork Experts (CCIE), ready to assist you at every step of the process, from proof of concept and design to architecture, implementation, testing, and issue resolution.
Feel free to reach out to CDA to explore how we can support your needs further!